Give us a star ⭐️ on GitHub to support the project!
Evaluate, test, and monitor ML models from validation to production.
From tabular data to NLP and LLM. Built for data scientists and ML engineers.
Evaluate, test, and monitor ML models from validation to production. From tabular data to NLP and LLM. Built for data scientists and ML engineers.

Start with simple ad hoc checks. Scale to the complete monitoring platform. All within one tool, with consistent API and metrics.
Useful, beautiful, and shareable. Get a comprehensive view of data and ML model quality to explore and debug. Takes a minute to start.
GET STARTED

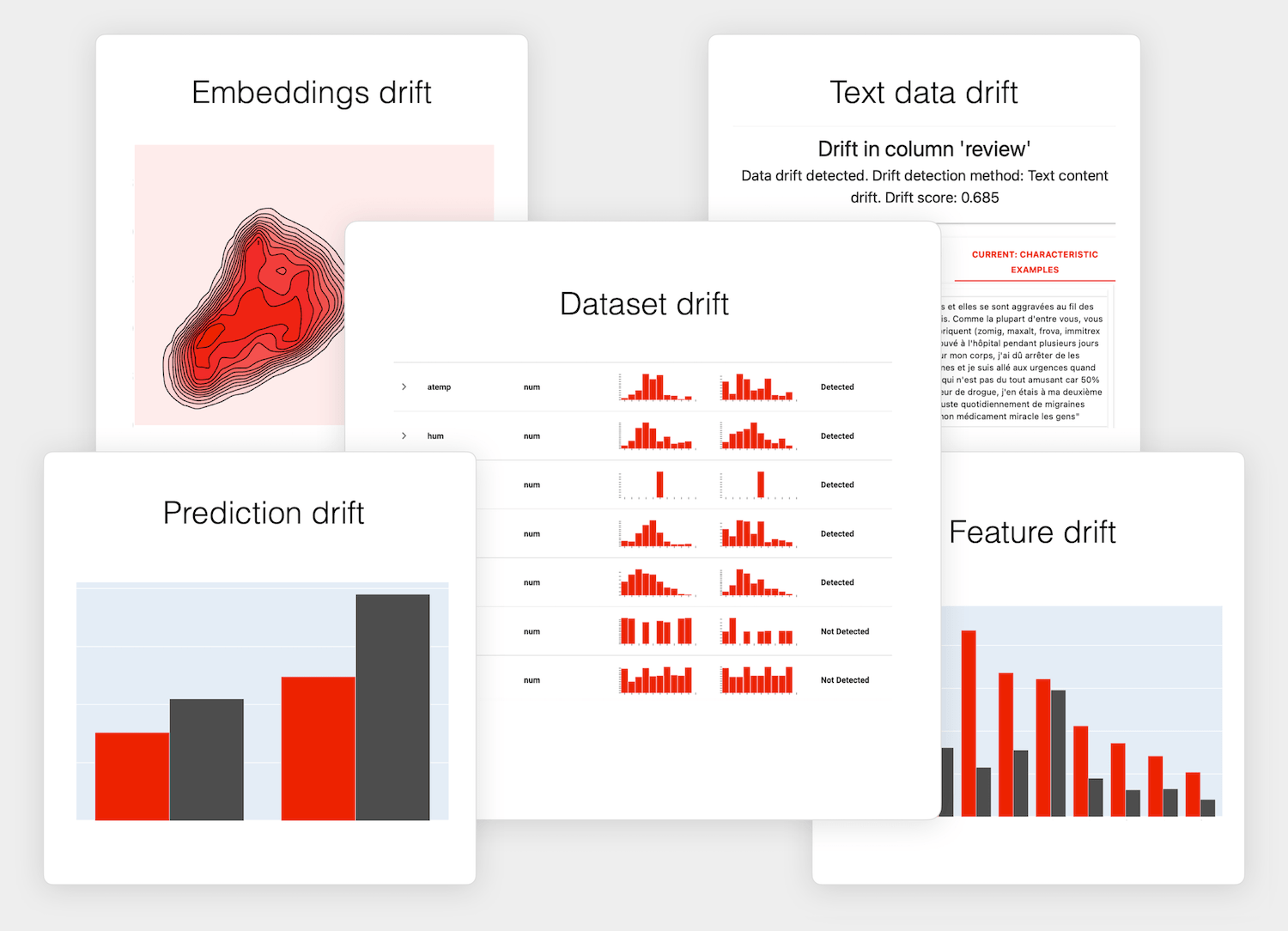
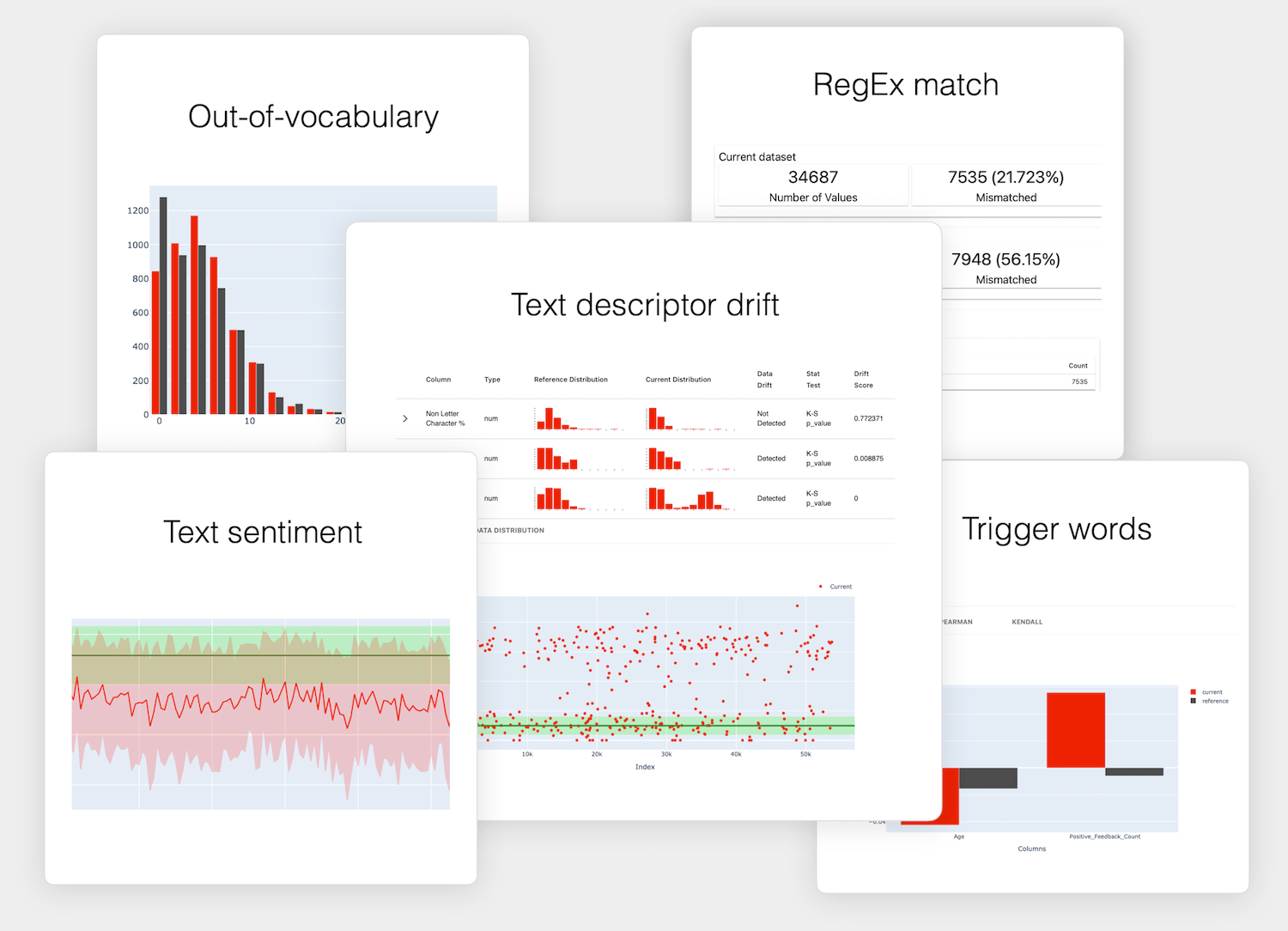
Test before you ship, validate in production and run checks at every model update. Skip the manual setup by generating test conditions from a reference dataset.
GET STARTEDMonitor every aspect of your data, models, and test results. Proactively catch and resolve production model issues, ensure optimal performance, and continuously improve it.
GET STARTED


Get support, contribute, and chat ML in production in our Discord community.
join discord
“We use Evidently daily to test data quality and monitor production data drift. It takes away a lot of headache of building monitoring suites, so we can focus on how to react to monitoring results. Evidently is a very well-built and polished tool. It is like a Swiss army knife we use more often than expected.”
Read the blog →
“We use Evidently to continuously monitor our business-critical ML models at all stages of the ML lifecycle. It has become an invaluable tool, enabling us to flag model drift and data quality issues directly from our CI/CD and model monitoring DAGs. We can proactively address potential issues before they impact our end users.”

“We use Evidently for continuous model monitoring, comparing daily inference logs to corresponding days from the previous week and against initial training data. This practice prevents score drifts across minor versions and ensures our models remain fresh and relevant. Evidently’s comprehensive suite of tests has proven invaluable, greatly improving our model reliability and operational efficiency.”

“Evidently is a fantastic tool! We find it incredibly useful to run the data quality reports during EDA and identify features that might be unstable or require further engineering. The Evidently reports are a substantial component of our Model Cards as well. We are now expanding to production monitoring.”
Read the blog →
“The user experience of our MLOps platform has been greatly enhanced by integrating Evidently alongside MLflow. Evidently's preset tests and metrics expedited the provisioning of our infrastructure with the tools for monitoring models in production. Evidently enhanced the flexibility of our platform for data scientists to further customize tests, metrics, and reports to meet their unique requirements.”

“Check out Evidently: I haven't seen a more promising model drift detection framework released to open-source yet!”

“Evidently is a first-of-its-kind monitoring tool that makes debugging machine learning models simple and interactive. It's really easy to get started!”

“I was searching for an open-source tool, and Evidently perfectly fit my requirement for model monitoring in production. It was very simple to implement, user-friendly and solved my problem!”

“I love the plug-and-play features for monitoring ML models.”
Turn predictions to metrics, and metrics to dashboards.

Decide what to collect: from individual metrics to complete statistical data snapshots. Customize everything or go with defaults.

Capture metrics, summaries, and test results with Evidently Python library. Send data from anywhere in your pipeline, batch or real-time.

Visualize the results on a monitoring dashboard. Explore your data over time, customize the views, and share with others on your team.
Add Evidently to existing workflows, no matter where you deploy.
