Let's say you trained a prediction model. And set it up for regular use. Welcome to machine learning in production!
Now, you rely on it to make business decisions. You have to maintain, retrain and keep an eye on your model.
What can go wrong with it, and how to keep track? Let's walk through an example.
It is a story of how we trained a model, simulated production use, and analyzed its gradual decay.
Code example: if you prefer to head straight to the code, open this example Jupyter notebook.
[fs-toc-omit]Want to learn more about ML monitoring?
Sign up for our Open-source ML observability course. Designed for data scientists and ML engineers. Yes, it's free!
Save my seat ⟶
The task at hand: bike demand forecasting
In this tutorial, we will work with a demand forecasting problem.
Dataset. We took a Kaggle dataset on Bike Sharing Demand. Our goal is to predict the volume of bike rentals on an hourly basis. To do that, we have some data about the season, weather, and day of the week.

Model. We trained a random forest model using data for the four weeks from January. Let's imagine that in practice, we just started the data collection, and that was all the data available. The performance of the trained model looked acceptable, so we decided to give it a go and deploy.
Feedback. We assume that we only learn the ground truth (the actual demand) at the end of each week.
That is a realistic assumption in real-world machine learning. Integrating and updating different data sources is not always straightforward. Even after the actual event has occurred! Maybe the daily usage data is stored locally and is only sent and merged in the database once per week.
A similar delay might occur when you generate the forecasts for different future periods. If you predict for a week ahead, this horizon becomes your waiting time.
Model checkup. Since the actuals are available only once per week, we decide to run a regular model analysis every time. There is no real-time monitoring. Instead, we schedule a job that generates a standard weekly report for the data scientist to look at.
How to analyze the model performance?
To analyze our model in production, we will use Evidently. It is an open-source tool that helps evaluate, test, and monitor ML models in production. Among other features, it generates interactive pre-built reports on model performance.
To run it, we prepare our performance data as a Pandas DataFrame.
It should include:
- model application logs—features that went into the model and corresponding prediction; and
- ground truth data—the actual number of bikes rented each hour as our "target."

You can follow our steps using this sample Jupyter notebook.
Let's look first at the performance of the model we created. Once we train the model, we can take our training dataset and generated predictions and specify it as the "Reference" data. Stay tuned: it will also help us refer to this data later.
We can select this period directly from the DataFrame since it has datetime as an index.
We also map the columns to show Evidently what each column contains and perform a correct analysis:
By default, Evidently uses the index as an x-axis in plots. In this case, it is datetime, so we do not need to add anything else explicitly. Otherwise, we would have to specify it in our column mapping.
Next, we call a corresponding report for regression models.
And display the results right in the Jupyter notebook.
We also save the generated report as an HTML file to be able to share it easily.
We can see that the model quality is acceptable, even though we only trained on four weeks of data!
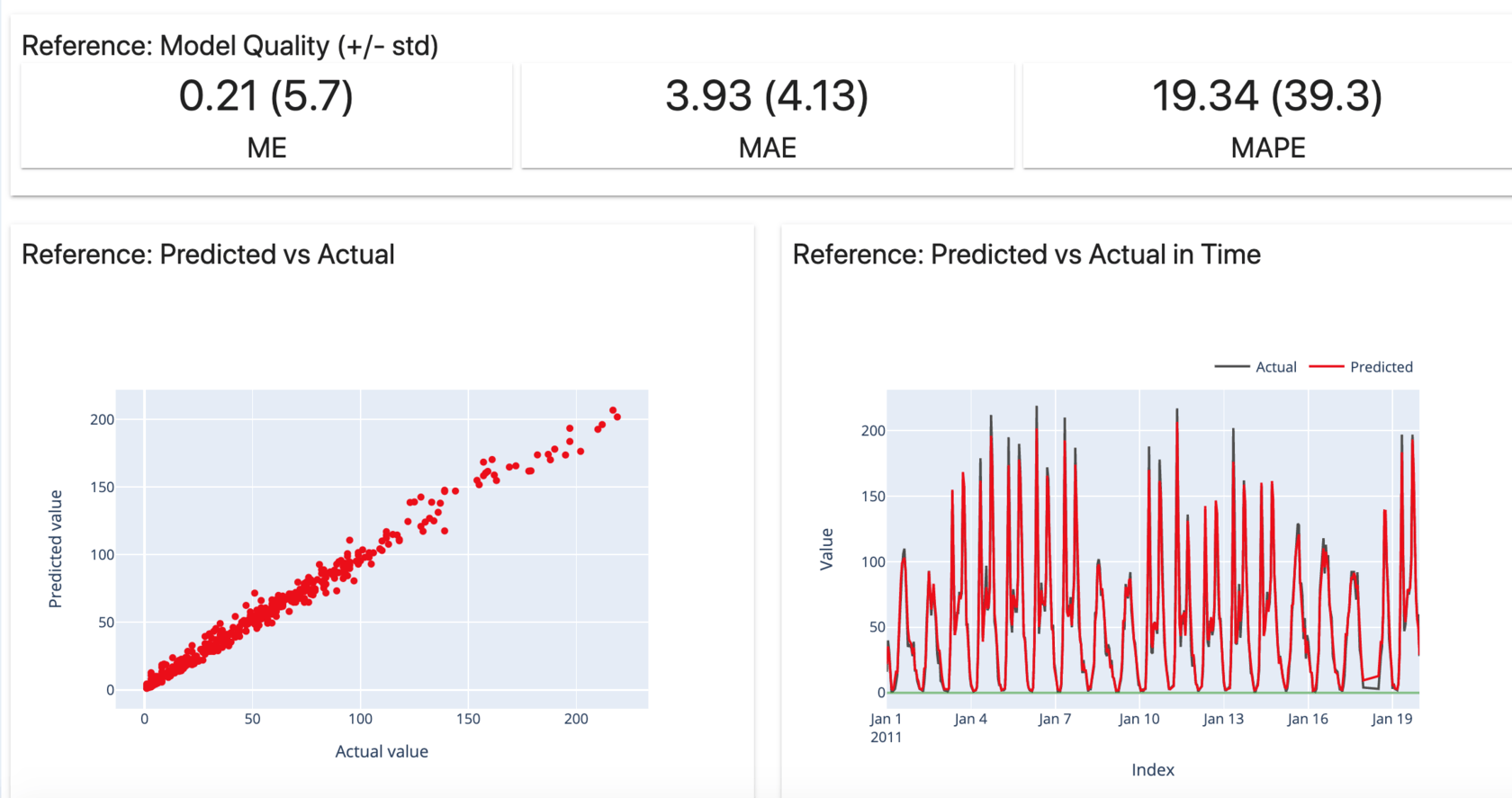
More good news: the error is symmetric and distributed around zero. There is no obvious under- or over-estimation.

We will continue treating this dataset from model performance in training as our "reference." It gives us a good feel of the quality we can expect from our model in production use. So, we can contrast the future performance against this benchmark.
Week 1: into the wild
Observing the model in production has straightforward goals. We want to detect if something goes wrong. Ideally, in advance.
We also want to diagnose the root cause and get a quick understanding of how to address it. Maybe, the model degrades too fast, and we need to retrain it more often? Perhaps, the error is too high, and we need to adapt the model and rebuild it? Which new patterns are emerging?
In our case, we simply start by checking how well the model performs outside the training data. Our first week becomes what would have otherwise been a holdout dataset.
We continue working with the sample Jupyter notebook. For demonstration purposes, we generated all predictions for several weeks ahead in a single batch. In reality, we would run the model sequentially as the data comes in.
To choose the period for analysis, we will indicate the rows in the DataFrame.
Let's start by comparing the performance in the first week to what we have seen in training. The first 28 days are our Reference dataset; the next 7 are the Production.
The report is up! We can quickly compare the Production performance to our Reference.
Some decay is expected, but things don't look so bad overall.

The error has slightly increased and is leaning towards underestimation.
Let's check if there is any statistical change in our target. To do that, we will generate the Target Drift report using a corresponding preset:
We can see that the distribution of the actual number of bikes rented remains sufficiently similar. To be more precise, the similarity hypothesis is not rejected. No drift is detected.

The distributions of our predictions did not change much either.

Despite this, a rational decision is to update your model by including the new week's data. This way, the model can continue to learn, and we can probably improve the error.
For the sake of demonstration, we'll stick to see how fast things go really wrong.
Moving on to the next week!
Week 2: failing to keep up
Once again, we benchmark the weekly performance against the reference.
At first glance, the model performance in the second week does not differ much.

MAE remains almost the same. But, the skew towards under-estimation continues to grow. It seems that the error is not random! On average, we underestimate by ten bikes.
To know more, we move to explore the additional plots in the report. We can see that the model catches overall daily trends just fine. So it learned something useful! But, at peak hours, the actual demand tends to be higher than predicted.

The error distribution plot shows how it became "wider," as we have more predictions with a high error. The shift to the left is visible, too. In some extreme instances, we have errors between 80 and 40 bikes that were unseen previously.

Let's check our target as well.
Things are getting interesting!
We can see that the target distribution is now different: the similarity hypothesis is rejected. Literally, people are renting more bikes. And this is a statistically different change from our training period.

But, the distribution of our predictions does not keep up! That is an obvious example of model decay. Something new happens in the world, but it misses the patterns.

It is tempting to investigate further. Is there anything in the data that can explain this change? If there is some new signal, retraining will likely help the model to keep up.
The Target Drift report has a section to help us explore the relationship between the features and the target (or model predictions).
When browsing through the individual features, we can inspect if we notice any new patterns. We know that predictions did not change, so we only look at the relations with the target.
For example, there is a shift towards higher temperatures (measured in Celsius) with a corresponding increase in rented bikes.

This is new to the model!
Maybe, it would pick up these patterns in retraining. But for now, we simply move on to the next week without any updates.
Week 3: when things go south
Okay, now things do look bad. On week 3, we face a major quality drop.

Both absolute and percentage errors grew significantly.
If we look at the plots, the model predictions are visibly scattered. We also face a new data segment with high demand that the model fails to predict.
But even within the known range of the target value, the model now makes errors. Things did change since the training.
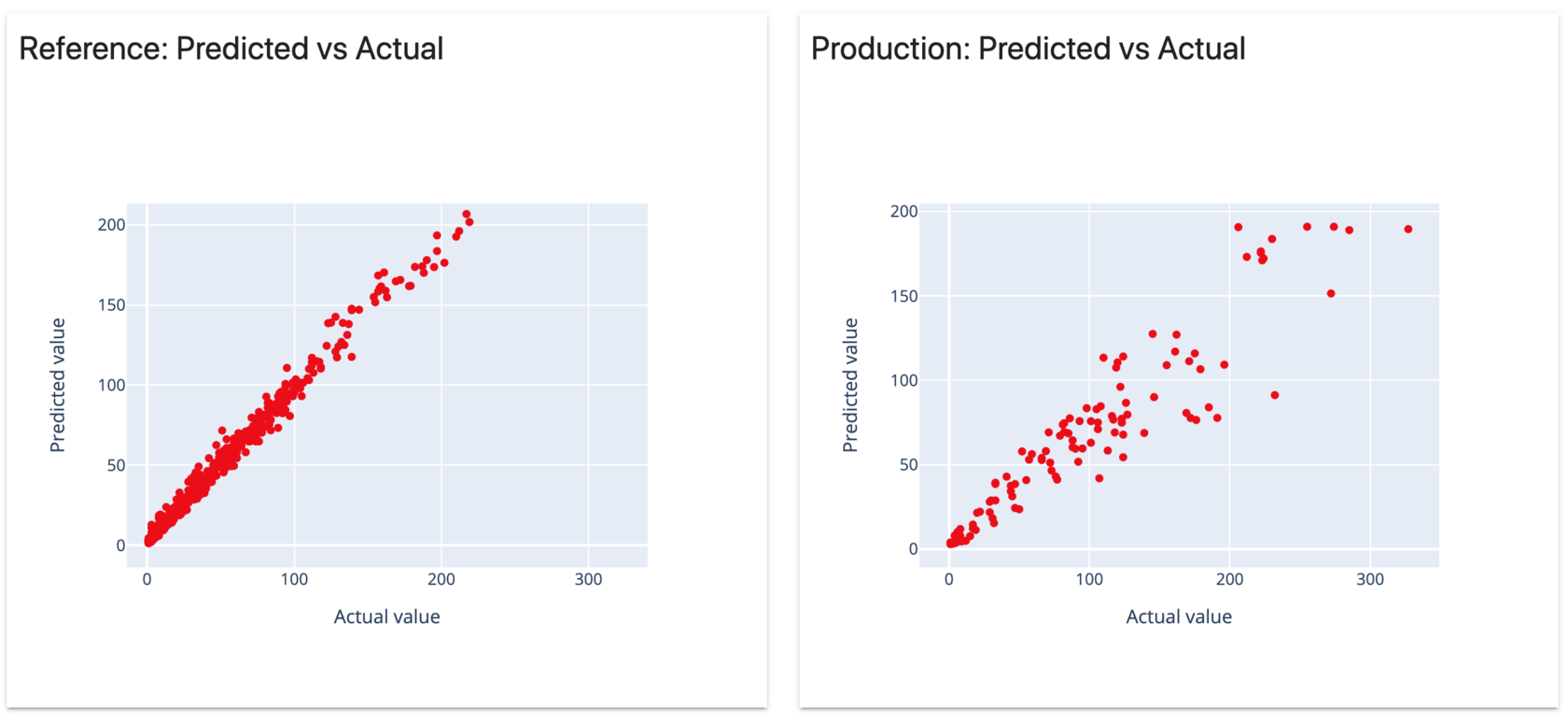
We can see that the model does not extrapolate well. The predicted demand stays within the same known range, while actual values are peaking.

If we zoom in on specific days, we might suggest that the error is higher on specific (active) hours of the day. We are doing just fine from 10 pm to 6 am!
However, we should be careful in interpreting such patterns. It might also be due to some other correlated factors, such as the warmer temperature at these same hours.

Evidently generates a few more plots to display the error. In the current context, these are different ways to paint the same story. We have a high error with a clear skew towards underestimation.


The early signs of these same model quality issues were visible in the past weeks. As the change accumulated, they got amplified.
The regression performance report also generates a set of insights to dive deeper into the underperforming segments. The goal is to explore if specific feature ranges can explain the error.
In our example, we particularly want to understand the segment where the model underestimates the target function.

The Error Bias table gives up more details.
We sort it by the "Range%" field. If the values of a specific feature are significantly different in the group where the model under- or over-estimates, this feature will rank high.
In our case, we can see that the extreme errors are dependent on the "temp" (temperature) and "atemp" (feels-like temperature) features.

In training, this has not been the case. We had all sorts of errors at different temperatures with no consistent pattern.
After this quick analysis, we have a more specific idea about model performance and its weaknesses. The model faces new, unusually high demand. Given how it was trained, it tends to underestimate it. On top of it, these errors are not at all random. At the very least, they are related to the temperature we observe. The higher it is, the larger the underestimation.
It suggests new patterns related to the weather that the model could not learn before. Days got warmer, and the model went rogue.
If we run a target drift report, we will also see a relevant change in the linear correlations between the feature and the target. Temperature and humidity stand out.
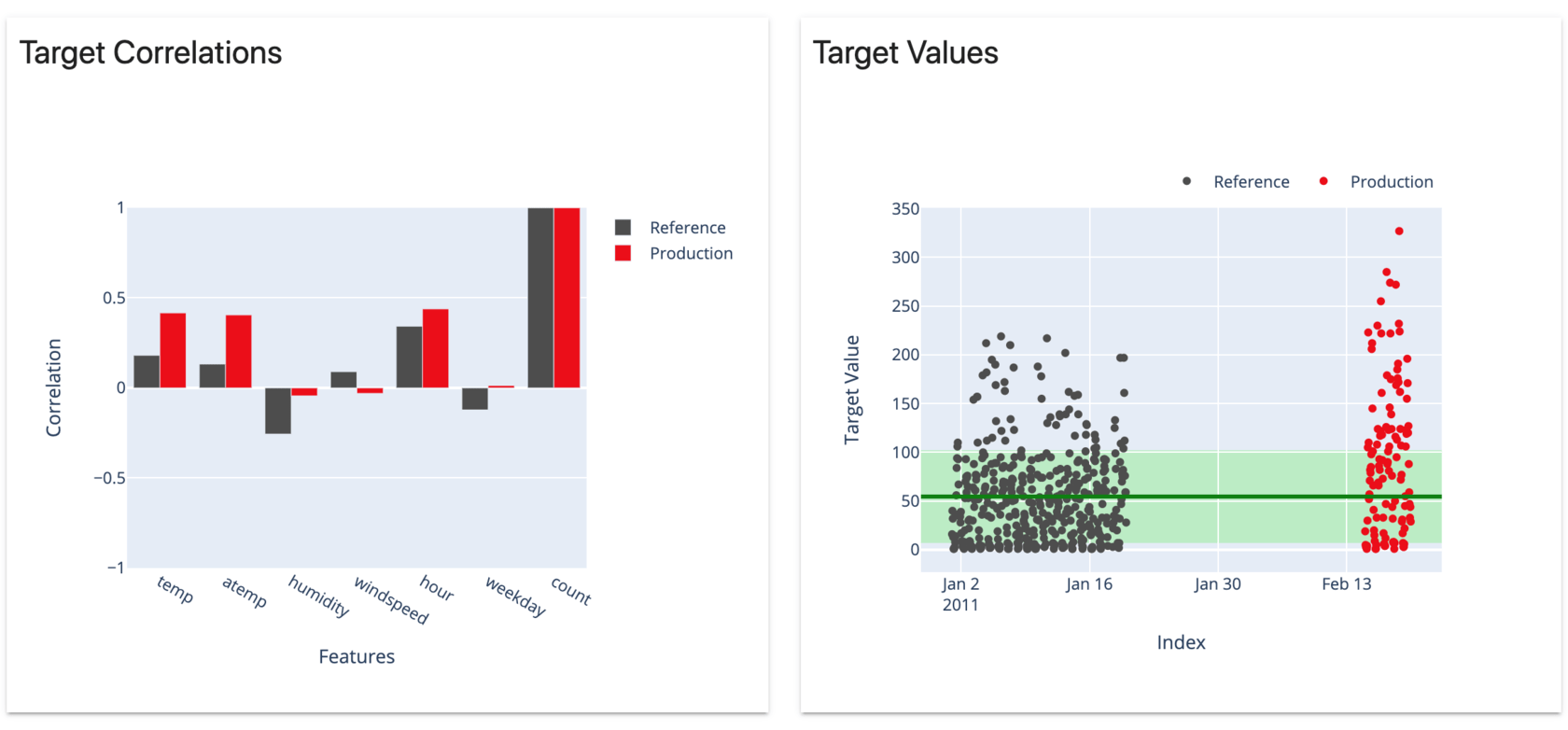
At this point, the model seems useless. It is a vivid example of how a model trained on a limited dataset fails to capture seasonal patterns.
We should retrain as soon as possible and do this often until we learn all the patterns. If we are not comfortable with frequent retraining, we might choose an algorithm that is more suitable for time series or is better in extrapolation.
Before it breaks: data and prediction drift
In practice, once we receive the ground truth, we can indeed course-correct quickly. If we retrained the model after the first week, it would likely have ended less dramatically.
But what if we do not have the ground truth available? Can we catch such decay in advance?
In this case, we can analyze the data drift. We do not need actuals to calculate the error. Instead, our goal is to see if the input data has changed.

Once again, let's compare the first week of production to our data in training.
We can, of course, look at all our features. But we can also conclude that categorical features (like "season," "holiday" and "workingday") are not likely to change. Let's look at numerical features only!
We specify these features so that the tool applies the correct drift detection method based on feature type and volume. It will be the Kolmogorov-Smirnov test in this specific case.
Then, we call the data drift report for the chosen period:
Once we display the report, it gives us the answer. Already during the first week, we can notice a statistical change in the feature distributions.

Let's zoom in on our usual suspect—temperature.
The report gives us two views on how the feature distributions evolve with time. We can notice how the observed temperature becomes higher day by day.
The values clearly drift out of our green corridor (one standard deviation from the mean) that we saw in training. Looking at the steady growth, we can suspect an upward trend.

In this plot, we also see: it is getting warmer. And that is not what our model is used to!

As we checked earlier, we did not detect drift in the model predictions after the first week. Given that our model is not good at extrapolating, we should not expect it.
The prediction drift might still happen, and signal issues like broken input data. We could have also observed it if we had a more sensitive model.
Predictions and data drift checks provide a valuable early signal for detecting and reacting to the change. It often makes sense to monitor both to be able to interpret them in context.
[fs-toc-omit]Support Evidently
Did you enjoy the blog? Star Evidently on GitHub to contribute back! This helps us continue creating free, open-source tools and content for the community.
⭐️ Star on GitHub ⟶
Closing thoughts
Frequent retraining is one way to address production model maintenance. Monitoring and observability add one more layer to assure model quality.
Why should we include it in our workflow?
- It speeds up debugging. Whenever your model fails, you need to identify the root cause. Pre-built dashboards make it faster.
- It shows the performance in detail. If you only rely on aggregate model performance in cross-validation, it can disguise important patterns. Your model can silently fail on specific segments and need rebuilding.
- It helps improve the model. You can explore where and how the model makes errors. It helps identify optimal model architecture, retraining schedule, generate ideas for feature engineering. Or, direct the right question to your subject matter experts.
- It makes you proactive. Changes in the data inputs can be a leading indicator of model quality. We want to catch issues before they lead to model failures.
Can I do the same for my model?
Of course! Go to Github or pip install evidently to be able to generate these reports for your models. If you deal with text data, you can also explore the NLP monitoring tutorial.



