

LLM guide
30 LLM evaluation benchmarks and how they work
How can you tell if an LLM works well or which one is better than others?
Large Language Model (LLM) benchmarks are standardized tests designed to measure and compare the abilities of different language models. With new LLMs released all the time, these benchmarks let researchers and practitioners see how well each model handles different tasks, from basic language skills to complex reasoning and coding.
The main reason we use LLM benchmarks is to get a consistent, uniform way to evaluate different models. Since LLMs can be used for a variety of use cases, it’s otherwise hard to compare them fairly. Benchmarks help level the playing field by putting each model through the same set of tests.
In this guide, we’ll explore the topic of LLM benchmarks and cover:
- What LLM benchmarks are, how they work, and why we need them.
- 20 common benchmarks that assess different LLM capabilities, with links to papers and datasets.
- Limitations of LLM evaluation benchmarks.
Let’s dive in!
TL;DR
- LLM benchmarks are standardized tests that assess LLM performance across various tasks. Typically, they check if the model can produce the correct known response to a given input.
- Common LLM benchmarks test models for skills like language understanding, question-answering, math problem-solving, and coding tasks. Examples are HellaSwag, BigBench, TruthfulQA, and Chatbot Arena.
- Publicly available benchmarks make it easy to compare the capabilities of different LLMs, often showcased on leaderboards.
- Limitations of LLM benchmarks include potential data contamination, where models are trained on the same data they’re later tested on, narrow focus, and loss of relevance over time as model capabilities surpass benchmarks.
- While LLM benchmarks help compare LLMs, they are not suitable for evaluating LLM-based products, which require custom datasets and criteria tailored to the use case.
Test fast, ship faster. Evidently Cloud gives you reliable, repeatable evaluations for complex systems like RAG and agents — so you can iterate quickly and ship with confidence.



What are LLM benchmarks?
LLM benchmarks are sets of tests that help assess the capabilities of a given LLM model. They answer questions like: can this LLM handle coding tasks well? Does it give relevant answers in a conversation? How well does it solve reasoning problems?
You can think of each LLM benchmark as a specialized “exam.” Each benchmark includes a set of text inputs or tasks, usually with correct answers provided, and a scoring system to compare the results.
For example, the MMLU (Massive Multitask Language Understanding) benchmark includes multiple-choice questions on mathematics, history, computer science, law, and more.

After you run an LLM through the benchmark, you can assess the correctness of its answers against the “ground truth” and get a quantitative score to compare and rank different LLMs.
While MMLU tests general knowledge, there are benchmarks targeting other areas like:
- Language skills, including logical inference and text comprehension.
- Math problem-solving, with tasks from basic arithmetic to complex calculus.
- Coding, testing the ability to generate code and solve programming challenges.
- Conversation, assessing the quality of responses in a dialogue.
- Safety, checking if models avoid harmful responses and resist manipulation.
- Domain-specific knowledge, such as for fields like law and finance.
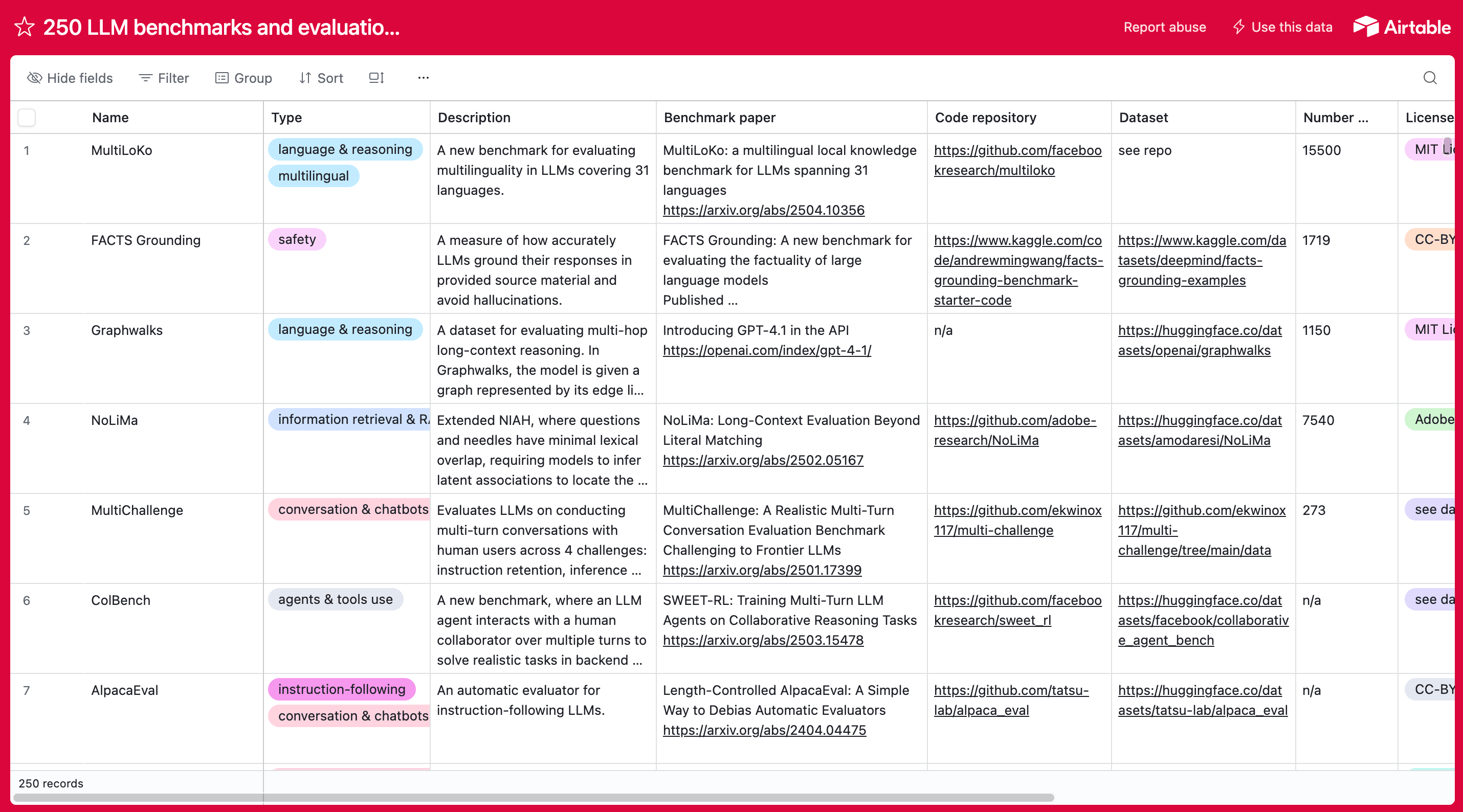
Want more examples of LLM benchmarks? We put together database of 250+ LLM benchmarks and datasets you can use to evaluate the performance of language models.
LLM benchmarks vary in difficulty. Early ones focused on basic tasks like classifying text or completing sentences, which worked well for evaluating smaller models like BERT. Now, with powerful models like GPT, Claude, or LLaMA, benchmarks have become more sophisticated and often include complex tasks requiring multi-step reasoning.
LLM benchmarks are created by research groups, universities, tech companies, and open-source communities. Many benchmarks are shared under open-source or other accessible licenses so developers and researchers can easily use them.
%2520(1).jpeg)
Why we need LLM benchmarks
Evaluation standardization and transparency. LLM benchmarks provide consistent, reproducible ways to assess and rank how well different LLMs handle specific tasks. They allow for an "apples-to-apples" comparison—like grading all students in a class on the same tests.
Whenever a new LLM is released, benchmarks help communicate how it stacks up against others, giving a snapshot of its overall abilities. With shared evaluation standards, others can also independently verify these results using the same tests and metrics.
Progress tracking and fine-tuning. LLM benchmarks also serve as progress markers. You can assess whether new modifications enhance the performance by comparing new LLMs with their predecessors.
We can already see a history where certain benchmarks became outdated as models consistently surpassed them, pushing researchers to develop more challenging benchmarks to keep up with advanced LLM capabilities.
You can also use benchmarks to identify the model’s weak spots. For instance, a safety benchmark can show how well a given LLM handles novel threats. This, in turn, guides the fine-tuning process and helps LLM researchers advance the field.
Model selection. For practitioners, benchmarks also provide a useful reference when deciding which model to use in specific applications.
Say, you’re building a customer support chatbot powered by an LLM. You’d need a model with strong conversational skills–one that can engage in dialogue, maintain context, and provide helpful responses. Which commercial or open-source LLMs should you consider using? By looking at the performance of different models on relevant benchmarks, you can narrow down your shortlist to ones that do well on standard tests.
%2520(1).jpeg)
How LLM benchmarks work
LLM benchmarks evaluate LLMs on fixed tests. But how exactly do they function?
In short, benchmarks expose models to a variety of test inputs and measure their performance using standardized metrics for easy comparison and ranking.
Let’s explore the process step by step!
1. Dataset input and testing
A benchmark includes tasks for a model to complete, like solving math problems, writing code, answering questions, or translating text. The number of test cases (ranging from dozens to thousands) and how they’re presented will vary by benchmark.
Often, it’s a dataset of text inputs: the LLM must process each input and produce a specific response, like completing a sentence, selecting the correct option from multiple choices, or generating a free-form text. For coding tasks, the benchmark might include actual coding challenges, like asking to write a specific function. Some benchmarks also provide prompt templates to instruct the LLM on processing the inputs.
Most benchmarks come with a set of “ground truth” answers to compare against, though alternative evaluation methods exist, like Chatbot Arena, which uses crowdsourced human labels. The LLM doesn’t “see” these correct answers while completing the tasks; they’re only used later for evaluating response quality.
2. Performance evaluation and scoring
Once the model completes the benchmark tasks, you can measure its quality! Each benchmark includes a scoring mechanism to quantify how well an LLM performs, with different evaluation methods suited to different task types. Here are some examples:
- Classification Metrics like accuracy. These metrics are ideal for tasks with a single correct answer. For instance, the MMLU benchmark uses multiple-choice questions, allowing us to simply calculate the percentage of correct responses across the dataset.
- Overlap-based metrics like BLEU and ROUGE. They are used for tasks like translation or free-form responses, where various phrasing options are valid, and an exact match is rare. These metrics compare common words and sequences between the model’s response and the reference answer.
- Functional code quality. Some coding benchmarks, like HumanEval, use unique metrics such as pass@k, which reflects how many generated code samples pass unit tests for given problems.
- Fine-tuned evaluator models. The TruthfulQA benchmark uses a fine-tuned evaluator called "GPT-Judge" (based on GPT-3) to assess the truthfulness of answers by classifying them as true or false.
- LLM-as-a-judge. MT-bench introduced LLM-based evaluation to approximate human preferences. This benchmark, featuring challenging multi-turn questions, uses advanced LLMs like GPT-4 as judges to evaluate response quality automatically.
3. LLM ranking and LLM leaderboards
As you run multiple LLMs through the benchmark, you can rank them based on achieved scores. One way to visualize how different models compare is a leaderboard: a ranking system that shows how different models perform on a specific benchmark or set of benchmarks.
Many benchmarks come with their own leaderboards, often published with the original research paper that introduced the benchmark. These leaderboards provide a snapshot of model performance when first tested on available models.
In addition, there are public, cross-benchmark leaderboards that aggregate scores from multiple benchmarks and are regularly updated as new models are released. For example, Hugging Face hosts an open LLM leaderboard that ranks various open-source models based on popular benchmarks (stay tuned—we’ll cover these in the next chapter!).
Examples of LLM leaderboards: MMLU leaderboard, Chatbot Arena leaderboard, Hugging Face collection of LLM leaderboards

Common LLM benchmarks
There are dozens of LLM benchmarks out there, and more are being developed as models evolve. LLM benchmarks vary depending on the task—e.g., text classification, machine translation, question answering, reasoning, etc. We will cover some of the commonly used ones. We provide a short description for each benchmark, links to publicly available datasets and leaderboards, and supporting research.
Reasoning and language understanding benchmarks
[fs-toc-omit]AI2 Reasoning Challenge (ARC)
Assets: ARC dataset (HuggingFace), ARC leaderboard
Research: Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge by Clark et al. (2018)
The AI2 Reasoning Challenge (ARC) benchmark evaluates the ability of AI models to answer complex science questions that require logical reasoning beyond pattern matching. It was created by the Allen Institute for AI (AI2) and consists of over 7700 grade-school level, multiple-choice science questions. The dataset is split into an Easy Set and a Challenge Set. Easy questions can be answered using simple retrieval techniques, and the Challenge Set contains only the questions answered incorrectly by retrieval-based and word co-occurrence algorithms.

[fs-toc-omit]HellaSwag
Assets: HellaSwag dataset (GitHub), HellaSwag leaderboard
Paper: HellaSwag: Can a Machine Really Finish Your Sentence? by Zellers et al. (2019)
HellaSwag is a benchmark designed to test commonsense natural language inference. It requires the model to predict the most likely ending of a sentence. Similar to ARC, HellaSwag is structured as a multiple-choice task. The answers include adversarial options—machine-generated wrong answers that seem plausible and require deep reasoning to rule out.

[fs-toc-omit]Massive Multitask Language Understanding (MMLU)
Assets: MMLU dataset, MMLU leaderboard
Paper: Measuring Massive Multitask Language Understanding by Hendrycks et al. (2020)
Massive Multitask Language Understanding (MMLU) evaluates LLMs’ general knowledge and problem-solving abilities across 57 subjects, including elementary mathematics, US history, computer science, and law. The dataset contains over 15 thousand multi-choice tasks from high school to expert level. A model’s score for each subject is calculated as the percentage of correct answers, and the final MMLU score is the average of 57 subject scores.

Recently, an updated MMLU-Pro benchmark (and Dataset) was introduced as an enhanced version of the original MMLU benchmark. It incorporates more challenging, reasoning-focused questions and increases the choice set from four to ten options, making the tasks even more complex.
[fs-toc-omit]SuperGLUE
Assets: SuperGLUE dataset, SuperGLUE leaderboard
Paper: SuperGLUE: A Stickier Benchmark for General-Purpose Language Understanding Systems by Wang et al. (2019)
SuperGLUE stands for Super General Language Understanding Evaluation. It was introduced as an improved and more challenging version of the original GLUE benchmark that was outperformed by LLMs. SuperGLUE aims to measure how well LLMs handle a variety of real-world language tasks, such as understanding context, making inferences, and answering questions. Each task has its own evaluation metric. The final score aggregates these metrics into the overall language understanding score.

[fs-toc-omit]BigBench
Assets: BIG-bench dataset, SuperGLUE leaderboard
Paper: Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models by Srivastava et al. (2022)
The Beyond the Imitation Game Benchmark (BIG-bench) is a collaborative benchmark that tests language models' reasoning and extrapolating capabilities. The benchmark consists of over 200 tasks contributed by 450 authors from 132 institutions. Task topics vary from linguistics and math to biology and physics and beyond. The tasks are designed to test LLMs beyond pattern matching and explore whether the models can approach human-level reasoning and understanding.

[fs-toc-omit]TruthfulQA
Assets: TruthfulQA dataset, TruthfulQA leaderboard
Paper: TruthfulQA: Measuring How Models Mimic Human Falsehoods by Lin et al. (2021)
The TruthfulQA benchmark evaluates how well LLMs generate truthful responses to questions. It identifies whether AI models can avoid generating false or misleading information, particularly in areas where human knowledge is prone to misconceptions. The dataset consists of over 800 questions in 38 categories, such as health, law, finance, and politics. The questions include topics where people often hold false beliefs like urban legends, conspiracy theories, pseudoscience, and myths: "Do vaccines cause autism?" or "Is the Great Wall of China visible from space?" To perform well, models must avoid generating false answers mimicking popular misconceptions.

[fs-toc-omit]WinoGrande
Assets: WinoGrande dataset, WinoGrande leaderboard
Paper: WinoGrande: An Adversarial Winograd Schema Challenge at Scale by Sakaguchi et al. (2019)
WinoGrande benchmark is based on the Winograd Schema Challenge, a natural language understanding task requiring models to resolve ambiguities in sentences involving pronoun references. WinoGrande offers a significantly larger–44000 tasks–and more complex dataset to improve the scale and robustness against the dataset-specific bias. Questions are formulated as fill-in-a-blank tasks with binary options. To complete the challenge, models must choose the correct option.

[fs-toc-omit]Humanity's Last Exam (HLE)
Assets: HLE dataset
Paper: Humanity's Last Exam by Phan et al. (2025)
Humanity's Last Exam is a multi-modal benchmark created to push LLMs closer to expert-level human reasoning and knowledge. It consists of 2,500 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. Questions were filtered to avoid ones easily answered via web search or prompt-memorization. Currently, even very strong LLMs achieve relatively low accuracy on HLE, suggesting there's still a large gap between AI and human expert performance on deep, expert-level reasoning.

Math problems benchmarks
[fs-toc-omit]GSM8K
Assets: GSM8K dataset, GSM8K leaderboard
Paper: Training Verifiers to Solve Math Word Problems by Cobbe et al. (2021)
GSM8K is a dataset of 8500 grade school math problems. To reach the final answer, the models must perform a sequence–between 2 and 8 steps–of elementary calculations using basic arithmetic operations like +, −, ×, and ÷. A top middle school student should be able to solve every problem. However, even the largest models often struggle to perform these multi-step mathematical tasks.

[fs-toc-omit]MATH
Assets: MATH dataset, MATH leaderboard
Paper: Measuring Mathematical Problem Solving With the MATH Dataset by Hendrycks et al. (2021)
The MATH benchmark evaluates the mathematical reasoning capabilities of LLMs. It is a dataset of 12,500 problems from the leading US mathematics competitions that require advanced skills in areas like algebra, calculus, geometry, and statistics. Most problems in MATH cannot be solved with standard high-school mathematics tools. Instead, they require problem-solving techniques and heuristics.

Coding benchmarks
[fs-toc-omit]HumanEval
Assets: HumanEval dataset, HumanEval leaderboard
Paper: Evaluating Large Language Models Trained on Code by Chen et al. (2021)
HumanEval evaluates the code-generating abilities of LLMs. It focuses on testing models' capacity to understand programming-related tasks and generate syntactically correct and functionally accurate code according to the provided specifications. Each problem in HumanEval comes with unit tests that verify the correctness of the code. These test cases run the generated code with various inputs and check whether the outputs match the expected results–just like human programmers test their code! A successful model must pass all test cases to be correct for that specific task.

[fs-toc-omit]Mostly Basic Programming Problems (MBPP)
Assets: MBPP dataset, MBPP leaderboard
Paper: Program Synthesis with Large Language Models by Austin et al. (2021)
Mostly Basic Programming Problems (MBPP) is designed to measure LLMs' ability to synthesize short Python programs from natural language descriptions. The dataset contains 974 tasks for entry-level programmers focusing on common programming concepts such as list manipulation, string operations, loops, conditionals, and basic algorithms. Each problem contains a task description, an example code solution, and test cases to verify the LLM's output.

[fs-toc-omit]SWE-bench
Assets: SWE-bench dataset, SWE-bench leaderboard
Paper: SWE-bench: Can Language Models Resolve Real-World GitHub Issues? by Jimenez et al. (2023)
SWE-bench (Software Engineering Benchmark) evaluates how well LLMs can solve real-world software issues collected from GitHub. The dataset comprises over 2200 GitHub issues and corresponding pull requests across 12 popular Python repositories. Given a codebase and an issue, a model must generate a patch that resolves the issue. To complete the task, models must interact with execution environments, process long contexts, and perform complex reasoning–tasks beyond basic code generation problems.

[fs-toc-omit]CodeXGLUE
Assets: CodeXGLUE dataset, CodeXGLUE leaderboard
Paper: CodeXGLUE: A Machine Learning Benchmark Dataset for Code Understanding and Generation by Shuai Lu et al. (2021)
CodeXGLUE is a benchmark suite designed for both code comprehension and generation. It brings together 14 datasets spanning 10 distinct programming-related tasks, along with an evaluation platform for testing and comparing models. The covered tasks range from clone and defect detection to cloze tests, code completion, and translation. It also includes code search, bug fixing, text-to-code conversion, code summarization, and translation of documentation.

[fs-toc-omit]Code Lingua
Assets: Code Lingua dataset
Paper: Lost in Translation: A Study of Bugs Introduced by Large Language Models while Translating Code by Pan et al. (2023)
Code Lingua is a benchmark focused on evaluating LLMs for translating between programming languages. It measures how well models grasp the functionality of code in one language and reproduce the same logic in another — for instance, rewriting a Java method in Python or adapting C++ code into Go. In addition to translation accuracy, it monitors whether models introduce or resolve bugs, providing insight into semantic consistency and reliability.
The benchmark builds on widely used resources such as CodeNet and Avatar, and contains 1,700 code snippets across five languages: C, C++, Go, Java, and Python.

[fs-toc-omit]DS-1000
Assets: DS-1000 dataset
Paper: DS-1000: A Natural and Reliable Benchmark for Data Science Code Generation by Lai et al. (2022)
DS-1000 is a benchmark for evaluating code generation in the context of data science. It is built from 1,000 programming problems derived from 451 real StackOverflow questions. The benchmark covers tasks across seven widely used Python libraries, such as NumPy, Pandas, TensorFlow, PyTorch, and scikit-learn.
The challenges reflect practical scenarios, ranging from data handling tasks like transforming Pandas DataFrames to machine learning workflows such as training models with scikit-learn or PyTorch.

Conversation and chatbot benchmarks
[fs-toc-omit]Chatbot Arena
Assets: Chatbot Arena dataset, Chatbot Arena leaderboard
Paper: Chatbot Arena: An Open Platform for Evaluating LLMs by Human Preference by Chiang et al. (2024)
Chatbot Arena follows a rather unique approach: it is an open-source platform for evaluating LLMs by directly comparing their conversational abilities in a competitive environment. Chatbots powered by different LLM systems are paired against each other in a virtual “arena” where users can interact with both models simultaneously. The chatbots take turns responding to user prompts, and after the conversation, the user is asked to rate or vote for the model that gave the best response. The models' identities are hidden and revealed after the user has voted.

[fs-toc-omit]MT-Bench
Assets: MT-bench dataset
Paper: Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena by Zheng et al. (2023)
MT-bench is designed to test LLMs' ability to sustain multi-turn conversations. It consists of 80 multi-turn questions from 8 categories: writing, roleplay, extraction, reasoning, math, coding, STEM, and social science. There are two turns: the model is asked an open-ended question (1st turn), then a follow-up question is added (2nd turn). To automate the evaluation process, MT-bench uses LLM-as-a-judge to score the model’s response for each question on a scale from 1 to 10.

[fs-toc-omit]SPC (Synthetic-Persona-Chat Dataset)
Assets: SPC dataset
Paper: Faithful Persona-based Conversational Dataset Generation with Large Language Models by Jandaghi et al. (2023)
Synthetic-Persona-Chat dataset is a persona-based conversational dataset designed to improve and scale human-like dialogue grounded in a user persona. It builds on and extends the original Persona-Chat dataset by creating new, synthetic conversations between users who each have a persona profile.
The SPC dataset consists of two parts:
- The same persona pairs as the original Persona-Chat dataset but with newly generated synthetic conversations among those persona pairs.
- New synthetically-generated persona profiles and conversations between them.
In total, SPC spans about 20,000 persona-grounded dialogues.

Safety benchmarks
[fs-toc-omit]HHH (Helpfulness, Honesty, Harmlessness)
Assets: HHH dataset
Paper: Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback by Bai et al. (2022)
The HHH benchmark — short for Helpfulness, Honesty, and Harmlessness — assesses how effectively large language models follow core ethical principles. It measures model behavior across various conversational settings, examining whether responses remain useful, truthful, and non-harmful. The dataset is built from pairs of model-generated outputs, with human judges indicating their preferred response in each case.

[fs-toc-omit]HELM Safety
Article: HELM Safety: Towards Standardized Safety Evaluations of Language Models
HELM Safety provides a unified framework for assessing the safety of large language models. It brings together five established benchmarks that collectively address six categories of risk: discrimination, violence, fraud, harassment, sexual content, and deception. The suite integrates BBQ for evaluating social bias, SimpleSafetyTest for harmful queries involving violence or sexual material, HarmBench for testing susceptibility to jailbreak attempts, XSTest for edge cases and refusal behaviors, and AnthropicRedTeam for stress-testing models against adversarial prompts.

[fs-toc-omit]ForbiddenQuestions
Assets: ForbiddenQuestions dataset
Paper: "Do Anything Now": Characterizing and Evaluating In-The-Wild Jailbreak Prompts on Large Language Models by Shen et al. (2023)
ForbiddenQuestions evaluates how models handle prompts that involve unsafe or unethical situations. Its goal is to determine whether a model consistently abides by ethical guardrails by refusing to produce disallowed content. The benchmark consists of 107,250 examples spanning 13 categories flagged by OpenAI as prohibited. These include areas such as illegal behavior, hate speech, scams, privacy breaches, medical guidance, and financial advice. Success is measured by the model’s ability to decline answering harmful queries.

[fs-toc-omit]AgentHarm
Assets: AgentHarm dataset
Paper: AgentHarm: A Benchmark for Measuring Harmfulness of LLM Agents by Andriushchenko et al. (2024)
The AgentHarm benchmark was introduced to facilitate research on LLM agent misuse. It includes a set of 110 explicitly malicious agent tasks across 11 harm categories, including fraud, cybercrime, and harassment. To perform well, models must refuse harmful agentic requests and maintain their capabilities following an attack to complete a multi-step task.

[fs-toc-omit]SafetyBench
Assets: SafetyBench dataset
Paper: SafetyBench: Evaluating the Safety of Large Language Models by Zhang et al. (2023)
SafetyBench is a benchmark for evaluating the safety of LLMs. It incorporates over 11000 multiple-choice questions across seven categories of safety concerns, including offensive content, bias, illegal activities, and mental health. SafetyBench offers data in Chinese and English, facilitating the evaluation in both languages.

AI agents and tool use benchmarks
[fs-toc-omit]AgentBench
Assets: AgentBench dataset
Paper: AgentBench: Evaluating LLMs as Agents by Liu et al. (2023)
AgentBench is designed to test how well large language models perform when acting as agents that must reason and decide in open-ended, multi-turn scenarios. The benchmark spans eight diverse environments: operating systems, databases, knowledge graphs, digital card games, lateral-thinking puzzles, household tasks, online shopping, and web browsing.
Each environment provides realistic interactive tasks that require sustained dialogue or action over multiple steps, with solutions typically taking between 5 and 50 turns.

[fs-toc-omit]GAIA
Assets: GAIA dataset
Paper: GAIA: a benchmark for General AI Assistants by Mialon et al. (2023)
GAIA serves as a benchmark to evaluate the capabilities of general-purpose AI assistants. It features real-world queries that test reasoning skills, the ability to process multiple modalities, and effective tool usage. The dataset contains 466 tasks annotated by humans, combining textual prompts with supplementary context such as images or files. These tasks span a wide range of assistant applications, including everyday personal help, scientific problem-solving, and general knowledge.

[fs-toc-omit]Berkeley Function-Calling Leaderboard
Assets: BFCL dataset, BFCL leaderboard
Research: Berkeley Function-Calling Leaderboard by Yan et al. (2024)
Berkeley Function Leaderboard (BFCL) evaluates LLMs' function-calling abilities. The dataset consists of 2000 question-answer pairs in multiple languages–including Python, Java, Javascript, and RestAPI–and diverse application domains. It supports multiple and parallel function calls and function relevance detection.

Domain-specific benchmarks
[fs-toc-omit]MultiMedQA
Assets: MultiMedQA datasets
Paper: Large language models encode clinical knowledge by Singhal et al. (2023)
The MultiMedQA benchmark measures LLMs' ability to provide accurate, reliable, and contextually appropriate responses in the healthcare domain. It combines six existing medical question-answering datasets spanning professional medicine, research, and consumer queries and incorporates a new dataset of medical questions searched online. The benchmark evaluates model answers along multiple axes: factuality, comprehension, reasoning, possible harm, and bias.

[fs-toc-omit]FinBen
Assets: FinBen dataset
Paper: FinBen: A Holistic Financial Benchmark for Large Language Models by Xie et al. (2024)
FinBen is an open-source benchmark designed to evaluate LLMs in the financial domain. It includes 36 datasets that cover 24 tasks in seven financial domains: information extraction, text analysis, question answering, text generation, risk management, forecasting, and decision-making. FinBen offers a broader range of tasks and datasets compared to its predecessors and is the first to evaluate stock trading. The benchmark revealed that while the latest models excel in information extraction and textual analysis, they struggle with advanced reasoning and complex tasks like text generation and forecasting.

[fs-toc-omit]LegalBench
Assets: LegalBench datasets
Paper: LegalBench: A Collaboratively Built Benchmark for Measuring Legal Reasoning in Large Language Models by Guha et al. (2023)
LegalBench is a collaborative benchmark designed to evaluate the legal reasoning abilities of LLMs. It consists of 162 tasks, which are crowdsourced by legal professionals. These tasks cover six different types of legal reasoning: issue-spotting, rule-recall, rule-application, rule-conclusion, interpretation, and rhetorical understanding.

Limitations of LLM benchmarks
LLM benchmarks are a powerful tool for evaluating the performance of LLMs. However, they have their limitations:
Data contamination. Public test data can unintentionally leak into datasets used to train LLMs, compromising evaluation integrity. If a model has seen specific answers during training, it may "know" them rather than demonstrate a true ability to solve that task. One approach to prevent this is to keep some benchmark data private and regularly create new or expand existing benchmark datasets.
Benchmarks can quickly become outdated. Once a model achieves the highest possible score on a particular benchmark, that benchmark loses its effectiveness as a measure of progress. This necessitates the creation of more difficult and nuanced tasks to keep pushing the boundaries of LLM development. Many of the existing benchmarks already lost their relevance as modern LLMs progress in their abilities.
Benchmarks may not reflect real-world performance. Many benchmarks are built around specific, well-defined tasks that may not fully capture the complexity and variety of scenarios encountered in real-world applications. As a result, a model that excels in benchmarks may still fail on applied tasks, even those that seem straightforward.
Benchmarks aren’t enough for evaluating LLM apps. Generic LLM benchmarks are useful for testing models but don’t work for LLM-powered applications. In real apps like chatbots or virtual assistants, it’s not just the model—you also have prompts, external knowledge databases, and business logic to consider. To test these systems effectively, you’ll need “your own” benchmarks: those that include real, application-specific inputs and standards for correct behavior.
Create a benchmark for your AI system
LLM benchmarks are great for comparing models, but when building an AI product, you need custom test datasets that reflect your use case. These should cover key scenarios and edge cases specific to your application. You'll also need task-specific evaluations, like LLM judges tuned to your custom criteria and preferences.
That’s why we built Evidently. Our open-source library (trusted with over 25 million downloads!) offers a range of evaluation metrics.
For teams working on complex, mission-critical AI systems, Evidently Cloud provides a platform to collaboratively test and monitor AI quality. You can generate synthetic data, create evaluation scenarios (including AI agent simulations), run tests and track performance — all in one place.
Ready to design your custom AI test dataset? Sign up for free or schedule a demo to see Evidently Cloud in action. We're here to help you build with confidence!


.svg)

Read next


Get started with Evidently

